3.1 데이터 전처리 기본
키워드 : 데이터 전처리, head(), describe(), corr(), info(), shape, value_counts(), isnull().sum(), unique(), nunique(), dropna(), drop(), replace(), fillna(), 데이터 변환, 인코딩, 결측값, 이상치, 원핫인코딩, 레이블 인코딩, 스케일링, 표준화, 정규화, 머신러닝, 딥러닝, AI, 파이썬, 데이터 분석, 데이터 시각화, EDA, 데이터 수집, 데이터 모델링
01. 데이터 전처리 정의 및 순서
데이터를 분석하기 위해서는 당연하게 데이터가 필요합니다. 데이터를 얻은 후에, 우리가 데이터를 분석하기 위해서는 데이터가 어떤 경향성을 띄고 있는지 (예를 들면 너무 한쪽으로 치우쳐 있지는 않는지 등) 전반적인 경향성을 파악할 필요가 있습니다. 우리는 데이터를 어디에서나 얻을 수 있지만, 그 데이터가 깔끔하고 완전하게 정돈 및 처리되어 있는 경우는 거의 드물다고 볼 수 있습니다. 따라서 이를 전처리하는 과정이 필요합니다. 이 모든 것을 처리하는 과정을 ‘데이터 전처리’라고 합니다.
데이터를 전처리하기 위한 순서는 Description→ Info → Data Cleaning → Data Transformation입니다. 먼저 데이터가 어떤 식으로 구성되어있는지 파악하는 Description 단계를 거칩니다. 이후 데이터의 분포가 어떻게 되어있는지 파악하기 위한 Info 단계를 거칩니다. 다음으로 Data Cleaning(데이터 정제) 단계를 거칩니다. 이 데이터 정제를 하는 과정에서 어쩌면 가장 많은 시간이 소요될 수도 있습니다. 마지막으로 데이터를 분석에 적용할 수 있도록 변환하는 Data Transformation(데이터 변환)과정을 거치게 됩니다. 이 네 가지의 데이터를 처리하는 순서는 목적에 따라 변동될 수 있으며, 명확하게 구분될 필요는 없습니다.
02. Description 단계
'Description' 단계는 주로 데이터의 내용과 패턴을 탐색하고 이해하기 위해 사용됩니다. 이 단계에서는 데이터셋의 내용을 더 자세히 파악하고, 데이터의 특성과 분포를 분석합니다.
이 단계의 주요 목표는 데이터의 특이점, 이상치, 패턴, 경향 등을 발견하여 데이터셋의 특성을 파악하는 것입니다. 주로 시각화와 요약 통계를 사용하여 데이터셋의 특성을 탐색하고 분석 결과를 확인합니다. 여기서 사용될 수 있는 상자그림 분포 등의 시각화 기법은 EDA 파트에서 다뤘기 때문에, 이를 제외하고 나머지의 내용을 다루도록 할 것입니다.
이 단계에서 이용한 데이터는 타이타닉 데이터 중 train 데이터 입니다. 파일 다운로드 후 바탕화면에 파일을 위치한 후 사용합니다.
2.1 head()
.png)
데이터는 파이썬의 라이브러리 중 하나인 ‘pandas’의 read_csv 기능을 통해 읽어올 수 있습니다.
이 때 head() 기능을 이용하면 데이터 프레임의 상위 5개 열만 추출하여 확인할 수 있습니다. ( ) 안에 다른 숫자를 넣어 확인할 수 있는 행의 숫자를 변경할 수 있습니다. 이를 통해 데이터의 모양과 형태를 간략하게 확인할 수 있습니다. 비슷한 기능으로 tail()을 통해 마지막 5개의 데이터 행을 체크할 수 있습니다.
2.2 describe()
describe() 기능은 정수형 혹은 실수형의 값들의 통계 값을 전체적으로 파악할 수 있는 기능입니다. 위에서 확인했듯이 float이거나 int 값을 가지고 있는 열은 7개였는데요, 이 7개의 열값이 총 몇개인지 (count), 평균은 몇인지 (mean), 표준편차 값은 몇인지 (std), 최소값은 몇인지(min), 상위 25% 값은 몇인지 (25%) 상위 50% 값은 몇인지 (50%), 상위 75(%) 값은 몇인지(75%), 최대값은 몇인지(max) 의 정보를 얻을 수 있습니다.
.png)
2.3 corr()
corr()는 각 변수간의 상관계수값을 배출해주는 기능입니다. 이 때 문자형 특징을 가지고 있는 변수는 제외됩니다. 상관계수값은 1에 가까울 수록 강한 양의 선형 상관관계를 보이며, -1에 가까울 수록 음의 선형 상관관계를 보입니다. 0에 가까울 수록 비선형 관계를 가지고 있거나 선형관계를 띄고 있지 않다고 해석할 수 있습니다.
.png)
예를 들어 위의 결과표를 봤을 때, Plcass와 Fare의 상관관계가 -0.54로 그나마 강한 음의 선형 상관관계를 띄고 있다고 볼 수 있습니다.
03. Info 단계
'Info' 단계는 데이터의 구조와 속성에 초점을 맞추어 데이터셋을 요약합니다. 주로 데이터셋의 구성 정보를 확인하고, 열의 데이터 타입, 결측치 여부, 비어있지 않은 값의 개수 등을 파악합니다. 데이터셋의 크기, 열의 수, 기본 통계 정보 등을 확인하여 데이터셋의 전반적인 정보를 파악하는 것이 목표입니다.
'Description' 단계는 데이터셋의 내용과 패턴을 발견하고 분석하여 데이터의 특성을 이해하는 데 중점을 둔 반면, 'Info' 단계는 데이터의 구조와 속성을 파악하여 데이터셋의 전반적인 형태와 특성을 파악하는 데 중점을 둡니다. 이 두 단계를 조합하여 데이터를 더 깊이 있는 방식으로 분석하고 전처리 단계에 활용할 수 있습니다.
3.1 info()
info() 는 각 열의 정보를 한눈에 알려줍니다. Column을 통해 어떤 열이 있는지 알 수 있으며, Non-null count를 통해 어떤 열이 null 값이 있는지 알 수 있습니다. 예를 들어 Age 열은 non-null count가 714개밖에 되지 않습니다. 즉 100개 이상의 null 값이 존재한다는 것입니다. 마지막으로 D-type은 각 열이 숫자인지, 문자인지 등의 정보를 알 수 있는 칸입니다.
.png)
3.2 shape
shape 기능을 통해 이 데이터가 총 몇 행 몇 열인지 알 수 있습니다. 이 데이터의 경우 891행, 12열로 구성된 데이터임을 알 수 있습니다.
.png)
3.3 value_counts()
value_counts()의 기능을 특정 열에 한정시켜 이용하면 특정 열에 어떤 구성성분이 있고, 각 구성성분은 몇개로 구성되어 있는지 알 수 있습니다. 예를들어 ‘Sex’ 열의 경우 male 577개, female 314개로 구성되어 있음을 알 수 있습니다.
.png)
3.4 isnull().sum()
isnull()은 특정 행의 값이 null 이면 True, null이 아니면 False 형식의 Bool 형태로 데이터 값을 반환하게 하는 기능입니다. True는 1을, False는 0입니다. 여기에 .sum()기능을 추가하게 되면 True의 값을 각각 1로 처리하여 합을 하게 되고, 그 결과 null 값이 몇개인지 알 수 있게 됩니다. 이 데이터를 보면 Age 열에 null값이 177개, Cabin 열에 null값이 687개, Embarked 열에 null 값이 2개 있음을 알 수 있습니다.
.png)
3.5 unique()
unique()는 해당하는 열에 어떤 고유의 값이 있는지 알 수 있는 기능입니다. 예를 들어 ‘Embarked’ 열에는 ‘S’,’C’,’Q’ 그리고 nan 값이 있습니다.
.png)
3.6 nunique()
nunique()는 nan값이 아닌 고유의 값들이 총 몇개인지 알 수 있는 기능입니다. 위에서도 봤듯이 ‘Embarked’의 고유한 값은 3개가 있다는 것을 알 수 있습니다.
.png)
04. Data Cleaning(데이터 정제)
데이터 정제 단계에서는 불완전하거나 오류가 있는 데이터를 처리합니다. 데이터정제 단계는 결측값처리, 이상치 처리의 두가지 세부 단계로 이루어집니다.
4.1 결측값 처리
a. 제거
결측치를 처리하는 방법에는 크게 두가지 방법이 있습니다. 첫 번째는 제거입니다. 이는 결측값이 포함된 행 또는 열을 제거하는 것입니다. 데이터의 양이 충분하거나 해당 정보가 중요하지 않을 때 사용할 수 있습니다.
· dropna()
dropna()는 nan 값이 있으면 그 값을 지워주는 역할을 합니다. 이 코드에서는 ‘Cabin’ 열에서 nan 값을 지워주게 됩니다. inplace = True는 데이터 프레임 위에 변경사항을 그대로 변경하여 새로운 변수에 변경사항을 저장하지 않아도 되도록 해줍니다.
titanic_df.dropna(subset=['Cabin'], inplace=True)
· drop()
drop()을 통해 행 또는 열 전체를 삭제할 수도 있습니다. 여기에서는 ‘Ticket’ 열을 삭제해보도록 하겠습니다. 데이터 프레임을 확인해보면 Ticket 열이 사라져있는 것을 확인할 수 있습니다.
titanic_df.drop(columns = ['Ticket'],inplace=True)
b. 대체
두 번째는 대체로, 말그대로 결측값을 다른 값으로 대체하는 것입니다. 이에는 대표적으로 평균, 중앙값, 최빈값 등으로 대체하는 방법이 있습니다. 주로 평균 대체는 연속형 데이터, 최빈값 대체는 범주형 데이터에 사용됩니다. 또는 결측값 주변의 값들을 활용하는 방법도 있습니다. 다음은 대체를 할 수 있는 파이썬의 주요 기능입니다.
· replace()
replace()는 내가 원하는 값으로 값을 교체해주는 기능입니다. 다음은 replace를 통해 ‘Sex’의 열의 male을 0, female을 1로 바꿔보는 코드입니다.
titanic_df['Sex'] = titanic_df['Sex'].replace('male',0)
titanic_df['Sex'] = titanic_df['Sex'].replace('female',1)
replace의 기능을 이용하여 빈 값을 채울 수도 있습니다. 다음의 코드는 Embarked 열에 있는 공백값을 최빈값인 ‘S’로 교체하는 코드입니다.
import numpy as np
titanic_df['Embarked'] = titanic_df['Embarked'].replace({np.nan:'S'})
· fillna()
fillna()는 공백값을 특정 값으로 채우는 방법입니다. 아래의 코드를 살펴보면, Age 열의 평균값을 fillna를 통해 채웠습니다.
average_age = titanic_df['Age'].mean()
titanic_df['Age'] = titanic_df['Age'].fillna(average_age)
다음의 데이터 프레임을 통해 이때까지 결측치를 처리한 결과를 한눈에 볼 수 있습니다.
.png)
4.2 이상치 처리
이상치(Outlier)는 대부분 데이터 분포에서 벗어나 극단적으로 크거나 작은 값입니다. 이상치는 모델 성능을 왜곡시킬 수 있기 때문에 이를 처리 해야할 필요가 있습니다. 이상치를 감지한 후에는 이를 제거하거나 대체하는 방법을 사용하여 처리를 하도록 합니다.
05. Data Transformation(데이터 변환)
데이터 변환은 데이터를 분석이나 모델에 적용할 수 있도록 데이터를 변환하는 단계입니다. 크게 인코딩과 스케일링으로 나눌 수 있습니다.
5.1 인코딩
데이터 분석에서 "encoding(인코딩)"은 데이터를 컴퓨터가 이해하고 처리할 수 있는 형식으로 변환하는 과정을 의미합니다. 데이터를 분석하려면 종종 다양한 형식의 데이터를 일관된 방식으로 표현해야할 상황이 생기는데, 이 때 텍스트, 숫자, 범주형 변수 등 다양한 유형의 데이터를 적절하게 인코딩하여 분석에 활용할 수 있습니다.
이번 포스팅에서는 가장 자주 쓰이는 기법인 원핫인코딩과 레이블 인코딩을 활용하여 범주형 데이터를 모델에 적용 가능한 형태로 변환하는 실습을 진행해보고자 합니다.
a. 원-핫 인코딩(One-Hot Encoding):
원-핫 인코딩은 각 범주를 이진(0 또는 1) 형태의 벡터로 표현하는 방법입니다. 각 범주마다 새로운 이진 특성(열)을 생성하여 해당 범주에 해당하는 열만 1이고 나머지 열은 모두 0인 형태로 변환합니다. 주로 명목형 변수(범주 간 순서가 없는 경우)에 사용되며, 예를 들어 ['사과', '바나나', '오렌지']의 리스트를 원=핫 인코딩을 하면 다음과 같이 표기가 됩니다:
사과: [1, 0, 0], 바나나: [0, 1, 0], 오렌지: [0, 0, 1]
실습을 통해 원-핫 인코딩 과정을 보여드리기 위해 다시 가공 이전의 train.csv를 titanic_df2로 불러오도록 하겠습니다.

‘Embarked’ 변수를 보시면 범주형 변수임을 알 수 있는데요, 이 열을 원-핫 인코딩 해보도록 하겠습니다. 그 전에 ‘Embarked’ 행에 nan 값이 있기 때문에 제거한 후에 시작하겠습니다.
titanic_df2.dropna(subset=['Embarked'],inplace=True)
이제 원-핫 인코딩을 실행하기 위해 필요한 모듈을 임포트 해줍니다. 이번에는 sklearn이라는 라이브러리에서 원하는 모듈을 import 합니다.
.png)
네번째 줄을 보면 ColumnTransformer는 인코딩을 각 열에 적용해주는 것인데요, 이 때 OneHotEncoder을 [11] 열, 즉 ‘Embarked’ 열에만 적용해주겠다는 뜻입니다. reminder=’passthrough’는 11열 외의 나머지 열에는 적용하지 않고 그냥 지나쳐 달라는 뜻입니다. 우리가 만든 이 ct를 titanic_df2 데이터프레임에 fit_transform 과정을 거치게 되면 ‘Embarked’의 범주형 정보가 원-핫 인코딩되었음을 확인할 수 있습니다.
b. 레이블 인코딩(Label Encoding):
레이블 인코딩은 각 범주를 숫자로 매핑하여 변환하는 방법입니다. 이 방법은 각 범주마다 고유한 숫자를 할당하여 범주를 숫자로 대체합니다. 주로 범주 간의 순서나 계층적 구조를 가진 경우에 유용합니다. (예: 낮음, 중간, 높음) 그러나 범주 간의 순서가 없는 경우에 레이블 인코딩을 사용하면 모델이 잘못된 판단을 할 수 있기 때문에 주의해야 합니다. 예를 들어 ['사과', '바나나', '오렌지']의 범주형 데이터가 있을 때, 레이블 인코딩을 거치면 다음과 같이 인코딩이 됩니다:
사과: 1, 바나나: 2, 오렌지: 3
지금부터는 레이블 인코딩을 하는 방법에 대해 살펴보도록 하겠습니다. 이번에는 Sex 열을 레이블 인코딩해보도록 하겠습니다.
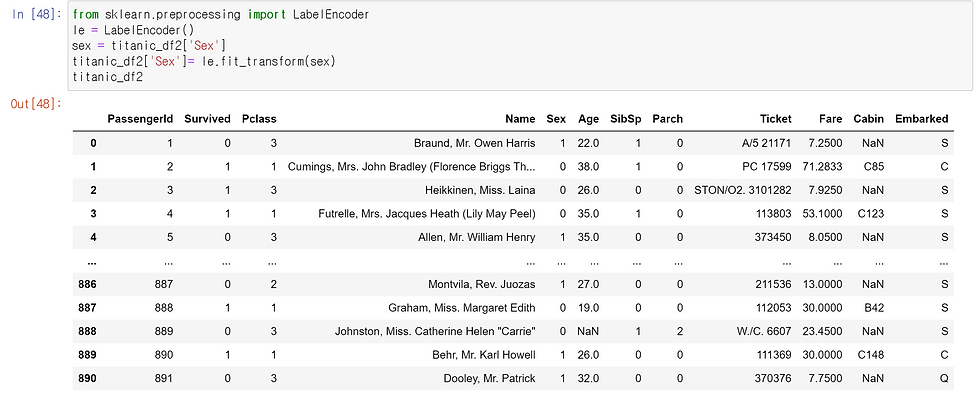.png)
먼저 sklearn의 preprocessing 에서 LabelEncoder을 임포트해줍니다. 그런 후 le라는 변수에 라벨 인코더를 넣어줍니다. 우리는 Sex 열의 정보를 인코딩할 것이기 때문에 sex 변수에 타이타닉 sex 열만 넣어줍니다. 그런 후 sex를 우리가 만들었던 le에 피팅 및 변환을 시켜줍니다. 이 과정을 통해 Sex의 정보가 라벨인코딩이 됩니다. 그러면 위에서 볼 수 있듯이 Sex의 정보가 0,1로 인코딩 되었음을 확인할 수 있습니다.
5.2 스케일링
머신러닝의 스케일링(scale) 단계는 데이터의 특성을 표준화하거나 정규화하는 과정을 의미합니다. 스케일링을 하는 이유는 다음과 같습니다. 먼저 모델 성능 향상에 도움이 됩니다. 일부 머신러닝 알고리즘은 데이터의 스케일이 다른 경우에 제대로 작동하지 않을 수 있기 때문입니다. 예를 들어, 경사 하강법을 사용하는 선형 회귀 모델은 스케일이 큰 특성이 있으면 수렴하는 데 어려움을 겪을 수 있습니다. 이 때 스케일을 조정하면 최적화 알고리즘이 더 잘 작동하고 모델이 빠르게 수렴할 수 있습니다.
두번째로는 특성 간의 상대적 중요성이 보존되기 때문입니다. 스케일을 조정하면 모든 특성이 동등한 가중치로 고려되도록 할 수 있습니다. 특성 간 스케일 차이가 크면 모델은 스케일이 큰 특성에 치우쳐서 학습되어 중요한 특성이 무시될 가능성이 있습니다. 이 외에도 모델의 성능과 안정성을 위한 다양한 이유로 스케일링을 합니다. 스케일링에도 다양한 종류가 있습니다. 아래는 스케일링의 일부 종류와 그에 대한 설명입니다.
a. 표준화(Standardization):
표준화는 데이터의 평균을 0으로, 표준편차를 1로 만들어 데이터를 정규분포 형태에 가깝게 변환하는 방법입니다. 특성별로 평균을 빼고 표준편차로 나누어 데이터를 스케일링합니다. 이 방법은 데이터가 정규분포를 따르는 경우 사용이 용이합니다.
이번에는 Age와 Fare 열에 대해서 표준화 스케일링을 해보도록 하겠습니다. 아래처럼 sklearn에서 StandardScaler를 임포트한 후, standard_scaler에 titanic_numeric을 fit_transfrom 시켜주면 아래의 결과처럼 Age와 Fare 데이터가 표준화되었음을 살펴볼 수 있습니다.
.png)
b. 정규화(Normalization):
.png)
정규화는 데이터의 값을 [0, 1] 범위로 조정하는 방법입니다. 각 특성의 최소값을 빼고, 범위(최대값 - 최소값)로 나누어 데이터를 스케일링합니다. 주로 데이터의 크기가 큰 경우에 사용이 용이합니다.
.png)
표준화와 같은 과정으로 진행을 하다보면 다음과 같이 0과 1사이로 정규화가 되었음을 알 수 있습니다. 또한 인코딩한 범주형 변수에는 스케일링을 하지 않으셔도 됩니다.
06. 참고자료